November 2025 M T W T F S S « Aug 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 Categories
- AP patterning (13)
- Blog (1)
- Chromatin (88)
- Conference Notes (72)
- Fly Work (54)
- General STORM (25)
- Genomics (134)
- Journal Club (22)
- Lab Meeting (66)
- Microscopy (79)
- Notes (1)
- probe and plasmid building (58)
- Project Meeting (3)
- Protocols (13)
- Research Planning (74)
- Seminars (21)
- Shadow Enhancers (59)
- snail patterning (40)
- Software Development (5)
- Summaries (1,412)
- Teaching (9)
- Transcription Modeling (40)
- Uncategorized (10)
- Web development (19)
Links
Tags
analysis cell culture cell labeling chromatin cloning coding communication confocal data analysis embryo collection embryo labeling figures fly work genomics hb image analysis image processing images in situs Library2 literature making antibodies matlab-storm meetings modeling MP12 mRNA counting Ph planning presentation probe making project 2 project2 result results sectioning section staining shadow enhancers sna snail staining STORM STORM analysis troubleshooting writing-
GitHub Projects
Monday 03/17/14
9:45a – 8:00p
Computer Maintenance
- security updates on Cajal + reboot
- security updates on Tuck – reboot postponed due to users still analyzing data
- write to CDW about
Data processing
- not all F12F11 data finished analyzing before files were split and deleted? Analyzing splitdax files on Tuck. — remember to reset region of interest for 256×256 on split files.
- still splitting multi-color data (will be running another 4 days or so probably)
- 140316_L3E7 data successfully split and averaged during acquistion, (yay!), now fitting data on Cajal
- run all basic analysis / plots on 140316_L3E7 data
- splitting 140313_L3E8 data
- run TimeAverageMovie on ‘L:\140313_L3E8\splitdax\’
- run dot fitting analysis on ‘L:\140313_L3E8\splitdax\’
- run CopyAndAnalyzeOnArrival on 140317_L3E7 data
Chromatin Project
Data analysis
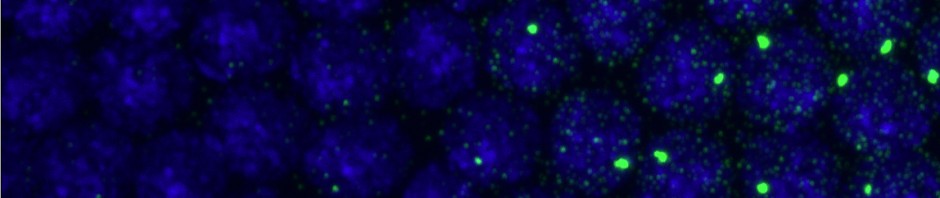
- ChromatinCroppin’ the F12F11 data
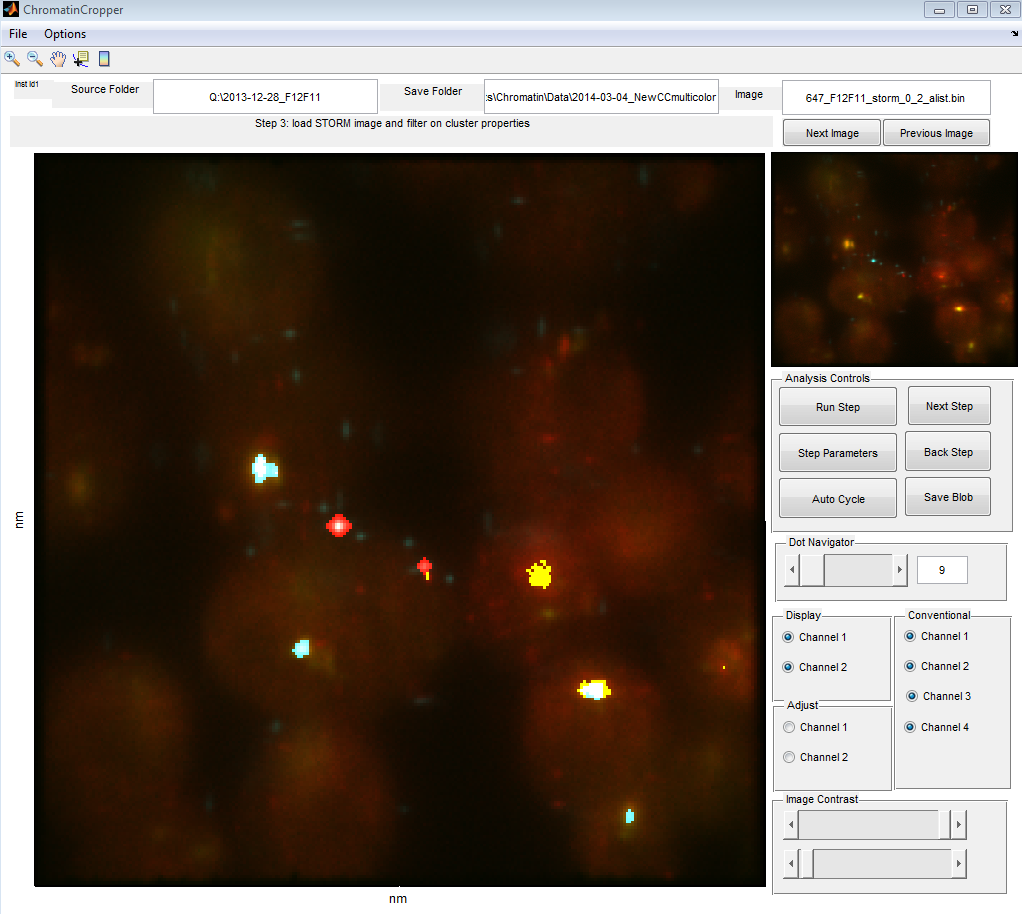
OligoPaints Project
- cy5 on DNA stats
- from movie recorded by Hao last year.
- re-ChromatinCropped S3 (405 + secondary), S1 (secondary), and S4 (2x cy5) data
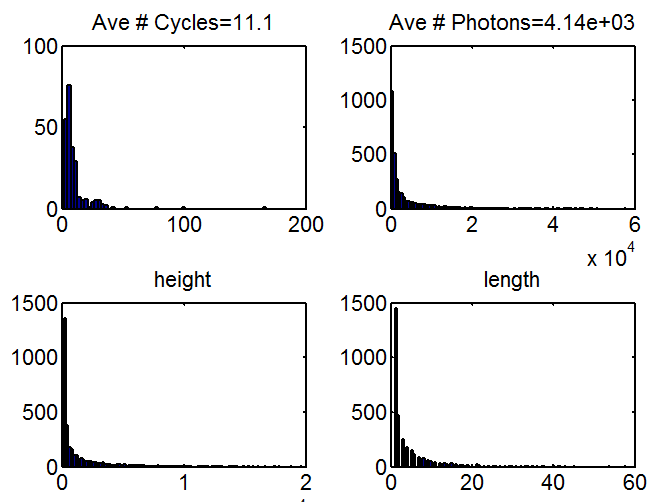
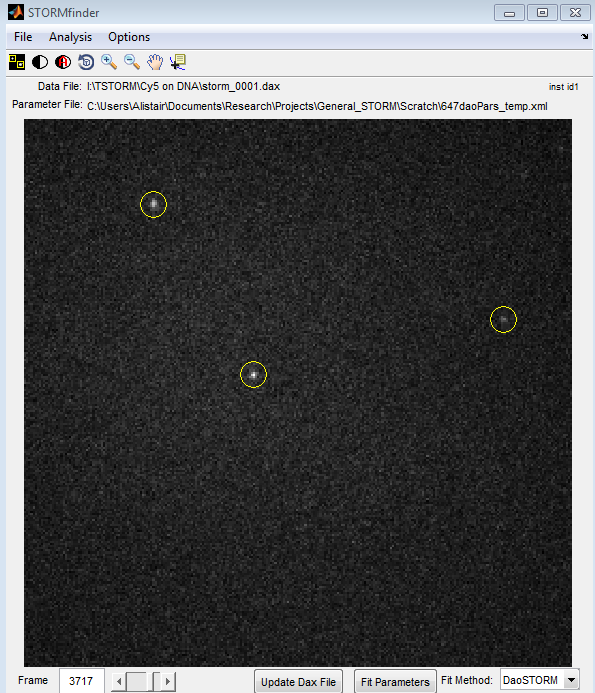
Protected: Overview of 140310 L4E4 data
Posted in Genomics
Tagged images, project 2, troubleshooting
Comments Off on Protected: Overview of 140310 L4E4 data
Sunday 03/16/14
10:30a – 6:00p
Goals
- flip fly stocks (done)
- passage cells (done)
- scheduling
- christia (May 17-20)
- dad’s conference (April 25th)
- dentist (May 7th)
More data processing!
- running splitdax on
140310_L4E4data - running bead averaging on
140310_L4E4data - analyzing averaged beads from
140310_L4E4 - Not all
140310_L4E4data copied from STORM4! copying remaining data. Need to relaunch all analysis 🙁 - running splitdax on dual color data — currently saves the 647 channel from the 750 movies because we haven’t told it to distinguish. This makes all the running a bit slower.
Issues with data
- 2014-01-14_F03-6_F04-7 beads alignment is clearly off — systematic shift in 750 647 observed
- 2014-01-15_F04-6_F03-7. bead alignment is okay, substantial shift (8-15 um?) in acquiring conventional images to STORM. Can’t use conventional masks! 🙁
- 2014-01-17_F03-6_F05-7. 750 data not analyzed (only beads are analyzed in 750, hopefully using the correct parameters).
Project 2
- looking at beads and setting up data run with Hao
Ph Project
- Ajaz found bug in k_d equation. Rerunning simulations. I think this actually expands the parameter space that gives the decreasing Ph behavior (as suits the logic). Previous dissociation rate had wrong dependence on mutant PH concentration in the cluster.
- more explorations.
Rethinking Project Organization
How do you organize your research projects?
For the last three years or so, I have adopted a project organization structure along the lines recommended by William Noble in PLoS CB: A Quick Guide to Organizing Computational Biology Projects.
The basic organizational idea here is that each project get’s its own directory. The top level of that directory is organized categorically. In my case I have Doc, Data, Results, Code and sometimes some other things. Code is version managed, and split into Functions (code that takes arguments and will be reused repeatedly) and Scripts code I intend to run only once. Since Scripts rapidly gets very large, and is run only once, maybe it shouldn’t be version managed, but I do occasionally re-run or write over scripts. Also version management acts as a backup if I actually push the versions somewhere (which I don’t at present), and a fail-safe against accidental deletion and overwriting of files. I recently added a third folder to Code for a number of projects called FigureCode. These are Scripts that start off in the Scripts folder, but once they are running and producing final versions of figures for that day which I am planning to present somewhere, these functional Figure producing scripts are saved in a new folder. All Scripts and FigureCode have the date (yymmdd) appended to the end of the filename.
I’ve encountered several problems having this system work with my needs. I take the time here to reflect on these problems and postulate some ways forward.
Big data projects
My projects folders live on in My Documents on C:\, whereas my data is stretched across (at present) 19 different external hard-drives (the most recent of which have 32Tb capacity). The data goes on these hard-drives as some function of the date on which it was collected, but get shuffled around to fill dead space (e.g. drive 10 has 500 GB free but tonight’s imaging session requires 600 GB but a few weeks later I have a 500 GB set that will just fit. Or I develop a cool compression algorithm for some data and decide some other data was a failed run and delete it, also opening up space on older disks which then gets filled). Consequently these data addresses aren’t permanent upon creation.
Ideally I would like the directory for the project to have links to the relevant data folders. Maybe this just requires more manual overhead to make sure I link and re-link files to the Data folder of the project — but that still sounds like a recipe for trouble.
It would be awesome instead to just tag data with a project name and have that automatically hook the data into the correct project folder. Maybe if my data folders include categorical tags (e.g. in the filename), I could write a little Daemon that looks through the data hard-drives and the data folders and updates all the links in the data-folders. This would be great to improve the tracking of datasets. One substantial challenge would be that some of the hard-drives go offline (to free up USB ports etc) and the Daemon would need to be able to tell did this move somewhere else or is it just disconnected. I think I could do it though — any file for which it can’t find a new link it just leaves the old link intact. Also need to deal with Windows assigning different drive letters to disks as you plug them into different ports (even though the folder has a common name). I’m sure I can write something smart enough to ignore the drive letter (search all) and just use the hard-drive disk name (e.g. Alistair2) though.
Folder names — dates vs. labels
William Noble uses categorical labels at top directory level, with date labels at the next level (e.g. Results\2014-02-14\). The date labeling is great, I like the alpha-numeric sorting by date, (year-month-day is a great idea), especially since date modified indexing reflects recent modifications note date results / data were taken, which is what I want. But a big folder full of dates is actually not too transparent — I stare at these and say which date did I take that data? and then flip through a bunch of them. Sometimes I get frustrated and go look up the date in my electronic lab notebook, but it’s nicer to have an at-a-glance system.
As a work around I have adopted a mixed date / categorical structure for this second level of organization, where some short tag is appended to the date to help trigger my memory about what it was: Results\2014-02-14_PHmutPSC.
Work not related to a specific project
I also spend a decent amount of time working on code that is not for a specific project (maybe that says something about my scientific efficiency). The idea though is that these additional coding projects make multiple aspects of my research faster more accurate and better documented. For example, several of my projects use STORM as an imaging method, and all my projects use Matlab to analyze data, so in collaboration with Jeff Moffitt (a fellow post-doc in the lab) I write code for a git repository we call matlab-storm. I also have a bunch of Matlab functions from my PhD work which I called Image-Analysis. These work alright as projects in their own right, since the scope is well defined. Though maybe they shouldn’t be since they aren’t really leading towards separate publications, though I suppose they could if we found the time to write it up.
A bigger challenge has been all the little functions I write to help with one project, which I then find myself re-using for other projects. My current (trial) solution for this is taking me further away from the basic projects organization I started with.
Master Toolbox Approach: matlab-functions
I recently started a new git repository called matlab-functions. As the name suggests, the goal of this project is to collect a large family of functions in one place. This way I don’t have to remember when I want to use that cool new function I wrote last week, if it was part of the Chromatin project Functions or the Ph Polymerization project Functions or whatever. The second and more important motivation was it makes it easier to share these functions. When it’s just me it’s not hard to just have all folders that contain custom functions added to my filepath via Matlab startup.m.
I’m also experimenting with more subfolders to organize these functions. These are reasonably sepecific — for instance, qPCR, BLAST and DeepSequencing are separate subfolders instead of having Genome Tools. More subfolders has the advantage of making it easier to understand what the project contains, since files are now grouped and organized. I guess ideally I would just tag files rather than put them in different subfolders and Windows Explorer window (or Nautilus / GNOME files on my Linuxbox) could display a list of tags instead of a list of folders, but operating systems seem to be behind the curve on this one.
This repository is now a private repo on Git with my research collaborators added as collaborators.
Old vs. new projects
As I accumulate projects in my Projects directory, it would be nice to see just the active ones (sort by date does okay here). Some of these projects are all published, pretty much wrapped up, and I haven’t done further work on them in years. Some are projects I started and abandoned. And some of course are the active ones that I hop between all the time.
Posted in Research Planning
Comments Off on Rethinking Project Organization
Protected: Overview of 140308 L4E3 data
Posted in Genomics
Tagged imaging, project 2, troubleshooting
Comments Off on Protected: Overview of 140308 L4E3 data
Friday 03/14/14
9:45a – 9:00p
Meetings
- meetings with G0 students, present lab research, discuss lab life
Computing resources
- Troubleshooting Tuck
- high flucutating memory despite little use
- memory drops precipitously when Hao closes matlab
- TSTORMdata drive is still flashes in use, despite no read-write activity
- crazy / slow behavior on tuck seems to be an incompatability of tuck with the 32TB tower.
PH project
- working on writeup of model details (see sharelatex project)
Posted in Summaries
Comments Off on Friday 03/14/14
Thursday 03/13/14
9:00a — 11:30p
communication
- Help Jaeger student with
Unsupervised_Dotfinding.m(see email)
meetings
- planning meeting for G0 presentation
- jeff will embed movies
- got slide from Bryan
- got movies from Colenso
- put in example images of chromatin
- need to rehearse talk!
- meeting for project2 — see notes
PH project
- primary focus today.
- see post
Project 2
- running more splitdax (I think this is never going to end)
- acquiring more data tonight
- move process-on-arrival scripts to matlab-functions