10:00a – 11:40p
Today
- working on journal club presentation (see googledocs)
- working on team project: see post
10:00a – 11:40p
10:00a – 11:15p
10:30a – 11:00p
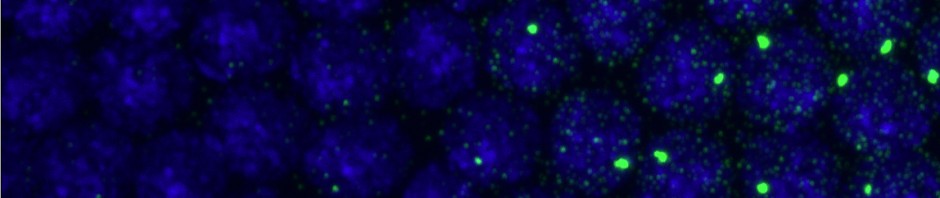
hsv(2) or hsv(4) map. But for single color I use hot(256).11:00a – 11:30p
ds tag. If they do they won’t be deleted.ds60 tagged downsampled file before deleting.(sick, working from home)
matlab-functions folder
'M:\2013-11-01_F07\splitdax'
'M:\2013-11-02_D11\splitdax'
'M:\2013-10-29_E10\splitdax'
'M:\2013-10-28_E08\splitdax'
'M:\2013-10-27_E01\splitdax'
'K:\2013-10-26_D12\splitdax'
'K:\2013-10-25_D11\splitdax'
'K:\2013-10-11_F10\splitdax'
'K:\2013-10-10_F11\splitdax'
'J:\2013-10-06_no405Primary\splitdax'
'J:\2013-10-05_E06\splitdax'
'J:\2013-10-04_G05\splitdax'
'J:\2013-10-03_E02\splitdax'
'J:\2013-10-02_D09\splitdax'
'J:\2013-10-01_G10\splitdax'
'H:\2013-10-09_F01V2\splitdax'
'H:\2013-10-07_F09\splitdax'
'H:\2013-09-24_F6-405\splitdax'
'H:\2013-09-23_F6\splitdax'
'H:\2013-09-09_G4\splitdax'
'H:\2013-09-05_G6\splitdax'
'H:\2013-09-04_G3\splitdax'
'H:\2013-09-02_G2\splitdax'
'H:\2013-08-22_Ubx\splitdax'
'H:\2013-08-21_AbdA\splitdax'
All 561quad_movies downsampled to 1 Hz, introduce gain of 4 to keep some dynamic range of data, original 60 Hz movie deleted. (Gain of 10 would saturate some frames of some movies).